Master Qlik QSDA2024 Exam with Reliable Practice Questions
A data architect executes the following script:

What will be the result of Table.A?
A)

B)
C)
D)
Correct : D
In the script provided, there are two tables being loaded inline: Table_A and Table_B. The script uses the Join function to combine Table_B with Table_A based on the common field Field_1. Here's how the join operation works:
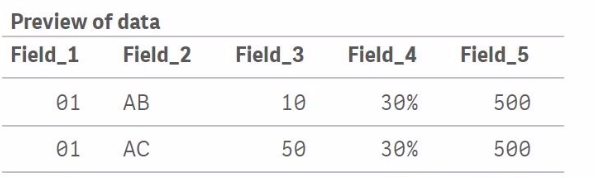
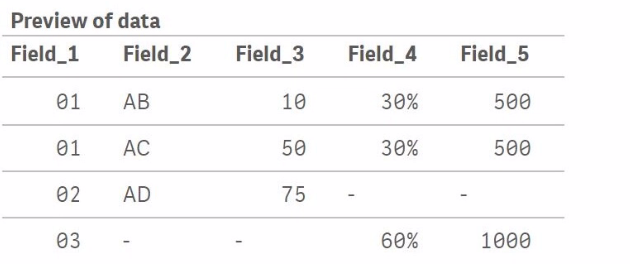
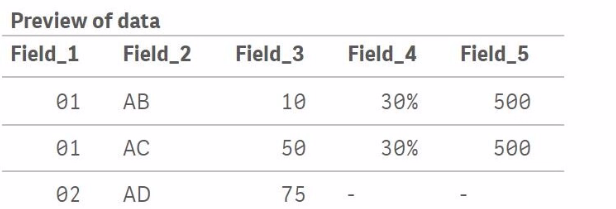
Table_A initially contains three records with Field_1 values of 01, 01, and 02.
Table_B contains two records with Field_1 values of 01 and 03.
When Join(Table_A) is executed, Qlik Sense will perform an inner join by default, meaning it will join rows from Table_B to Table_A where Field_1 matches in both tables. The result is:
For Field_1 = 01, there are two matches in Table_A and one match in Table_B. This results in two records in the joined table where Field_4 and Field_5 values from Table_B are repeated for each match in Table_A.
For Field_1 = 02, there is no corresponding Field_1 = 02 in Table_B, so the Field_4 and Field_5 values for this record will be null.
For Field_1 = 03, there is no corresponding Field_1 = 03 in Table_A, so the record from Table_B with Field_1 = 03 is not included in the final joined table.
Thus, the correct output will look like this:
Field_1 = 01, Field_2 = AB, Field_3 = 10, Field_4 = 30%, Field_5 = 500
Field_1 = 01, Field_2 = AC, Field_3 = 50, Field_4 = 30%, Field_5 = 500
Field_1 = 02, Field_2 = AD, Field_3 = 75, Field_4 = null, Field_5 = null
Start a Discussions
Exhibit.
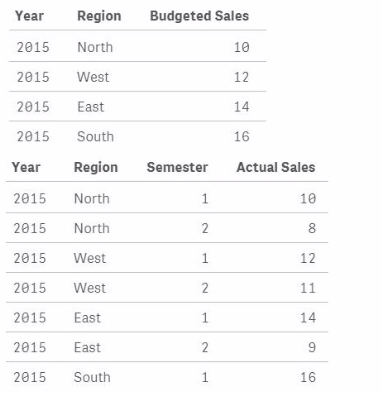
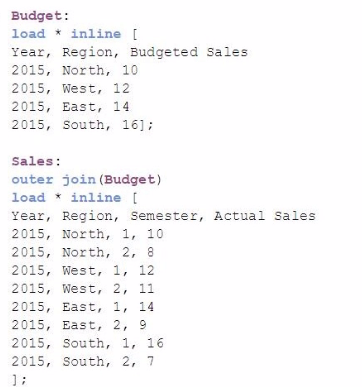
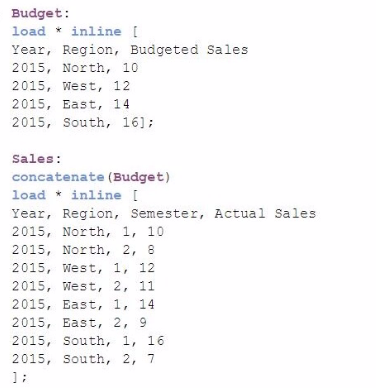
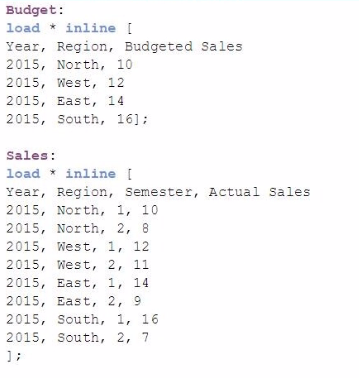
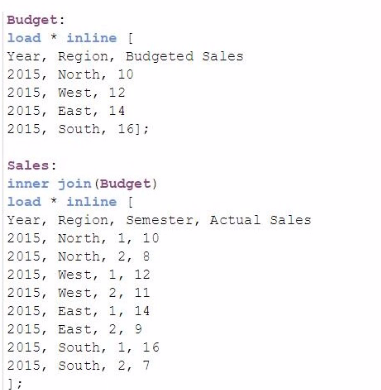
A data architect must load the two tables without creating a synthetic key. The data architect also must make sure expressions like Sum([Budgeted Sales]) are calculated correctly.
Which load script meets these requirements?
A)
B)
C)
D)
Correct : A
In the scenario provided, the data architect needs to load two tables (Budget and Sales) without creating a synthetic key, while ensuring that expressions like Sum([Budgeted Sales]) are calculated correctly.
Here is a breakdown of the options:
Option A (Outer Join): This option uses an outer join between the Sales table and the Budget table. While this approach will combine the tables based on the common fields (Year and Region), it will result in a single table that contains all fields from both tables. This approach prevents the creation of a synthetic key and retains all records from both tables, ensuring that all budgeted and actual sales data is available. As a result, calculations like Sum([Budgeted Sales]) will work correctly. This is the correct solution.
Option B (Concatenate): This option uses concatenate, which combines the tables by stacking them on top of each other as if they were one table. This approach will not prevent synthetic keys and could cause issues with calculations since Budgeted Sales and Actual Sales would be in the same column, leading to incorrect aggregation results.
Option C (Separate Load): This option simply loads the tables separately without any join or concatenation. While this will not create a synthetic key, it will result in two separate tables in the data model. Without any connection between these tables, calculations involving both Budgeted Sales and Actual Sales will not work correctly.
Option D (Inner Join): This option uses an inner join, which will combine only the records that match in both tables based on Year and Region. While this approach avoids synthetic keys, it may exclude records that do not have a corresponding match in both tables, potentially leading to incomplete data.
Given the requirements to avoid synthetic keys and ensure correct calculations, Option A (Outer Join) is the most appropriate approach. It ensures all relevant data is included and that the data model remains free from synthetic keys, while also allowing accurate calculations.
Start a Discussions
A company needs to analyze daily sales data from different countries. They also need to measure customer satisfaction of products as reported on a social media website. Thirty (30) reports must be produced with an average of 20,000 rows each. This process is estimated to take about 3 hours.
Which option should the data architect use to build this solution?
Correct : A
In this scenario, the company needs to analyze daily sales data from different countries and also measure customer satisfaction of products as reported on a social media website. This suggests that the data is likely coming from different sources, including possibly an API or a web service (social media website).
The Qlik REST Connector is the appropriate tool for this job. It allows you to connect to RESTful web services and retrieve data directly into Qlik Sense. This is especially useful for integrating data from various online sources, such as social media platforms, which typically expose data via REST APIs. The REST Connector enables the extraction of large datasets from these sources, which is necessary given the requirement to produce 30 reports with an average of 20,000 rows each.
Microsoft SQL Server is not suitable for fetching data from web services or social media platforms.
Qlik GeoAnalytics is used for mapping and geographical data visualization, not for connecting to RESTful services.
Mailbox IMAP is for connecting to email servers and is not applicable to the data extraction needs described here.
Thus, Qlik REST Connector is the correct answer for this scenario.
Start a Discussions
A data architect implements Section Access on an app to reduce the data for each user when the user logs in. Each user is allowed to see their specific territory only.
The app is set for a scheduled reload every three hours. Without Section Access added, the app loads successfully. When Section Access is added and the script runs, the app fails to load.
What is causing this issue?
Correct : B
When implementing Section Access in Qlik Sense, it is crucial that all accounts that need to access the data---including the service account that performs the scheduled reload---are included in the Section Access table. If the service account is not included, Qlik Sense will not be able to access any data, leading to a failure in the reload process.
Here's a breakdown of why the other options are less likely:
A . The ACCESS column in the Section Access table has been added in lowercase: This would generally result in a syntax error, but it would not allow the script to execute successfully without causing an immediate failure, unrelated to Section Access.
C . A user name listed in the Section Access table is spelled incorrectly: While this could lead to some users not having the correct access, it would not cause the entire reload to fail. The issue here is broader, affecting the entire application load process.
D . The data architect does not have rights to reload the app: If the architect did not have rights, the script would not run successfully even without Section Access.
The correct issue in this scenario is that the service account running the task is not included in the Section Access table. This is a common cause of load failures after adding Section Access. To resolve this, ensure that the service account is added with sufficient privileges in the Section Access table
Start a Discussions
Exhibit.
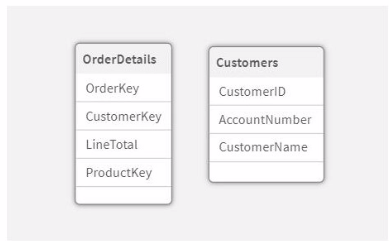
Refer to the exhibit.
A data architect is loading two tables into a data model from a SQL database. These tables are related on key fields CustomerlD and Customer Key.
Which script should the data architect use?
A)

B)

C)

D)

Correct : D
In the scenario, two tables (OrderDetails and Customers) are being loaded into the Qlik Sense data model, and these tables are related via the fields CustomerID and CustomerKey. The goal is to ensure that the relationship between these two tables is correctly established in Qlik Sense without creating synthetic keys or data inconsistencies.
Option A: Renaming CustomerKey to CustomerID in the OrderDetails table ensures that the fields will have the same name across both tables, which is necessary to create the relationship. However, renaming is done using AS, which might create an issue if the fields in the original data source have a different meaning.
Option B and C: These options use AUTONUMBER to convert the CustomerKey and CustomerID to unique numeric values. However, using AUTONUMBER for both fields without ensuring they are aligned correctly might lead to incorrect associations since AUTONUMBER generates unique values based on the order of data loading, and these might not match across tables.
Option D: This approach loads the tables with their original field names and then uses the RENAME FIELD statement to align the field names (CustomerKey to CustomerID). This ensures that the key fields are correctly aligned across both tables, maintaining their relationship without introducing synthetic keys or mismatches.
Start a Discussions