Master Nutanix NCP-MCI Exam with Reliable Practice Questions
An administrator needs to deploy an application with a large amount of data connected via Nutanix volumes.
Which two actions should the administrator take when designing the Volume Group? (Choose two.)
Correct : A, B
Distribute workload across multiple virtual disks: Use multiple disks rather than a single large disk for an application. Consider using a minimum of one disk per Nutanix node to distribute the workload across all nodes in a cluster. Multiple disks per Nutanix node may also improve an application's performance. For performance-intensive environments, we recommend using between four and eight disks per CVM for a given workload.
Enable RSS (Receive Side Scaling): Receive-side scaling (RSS) allows the system to use multiple CPUs for network activity. With RSS enabled, multiple CPU cores process network traffic, preventing a single CPU core from becoming a bottleneck. Enabling RSS within hosts can be beneficial for heavy iSCSI workloads. For VMs running in ESXi environments, RSS requires VMXNET3 VNICs. For Hyper-V environments, enable VMQ to take full advantage of Virtual RSS.
Start a Discussions
An administrator has a Custom backup application that requires a 2TB disk and runs m Windows. Throughput is considerably lower than expected.
The application was installed on a VM with the following configuration:
* FOU vCPUs with one core/vCPU
* 4GB of Memory
* One 50GB vDisk for the Windows installation
* One 2TB vDisk for the application
What is the recommended configuration change to improve throughput?
Start a Discussions
An administrator is implementing a VDI solution. The workload will be a series of persistent desktops in a dedicated storage container within a four-node cluster Storage optimizations should be set on the dedicated storage container to give optimal performance including during a node failure event
Which storage optimizations should the administrator set to meet the requirements?
Start a Discussions
After the initial configuration and upgrade of NCC, the administrator notices these critical alerts:
. IPMI 10.7.133.33 is using default password
. Host 10.7.133.25 is using default password
. CVM 10.7.133.31 is using default password
Which two initial cluster configuration tasks were missed during the deployment process? (Choose two.)
Correct : A, C
The critical alerts listed are indicating that the default passwords are still in use for IPMI, the host, and the Controller Virtual Machine (CVM). This suggests that the passwords for these components were not changed from the default during the initial cluster configuration and deployment process, which is a critical security practice.
A) CVM password changes: The alert for the CVM using the default password indicates that the CVM password has not been changed. It is a standard security measure to change default passwords to prevent unauthorized access.
C) Host password changes: Similarly, the alert for the host using the default password indicates that the default password for the host has not been updated. This applies to the passwords used to access the hypervisor host directly.
Changing default passwords is a critical step in securing the Nutanix environment. This is highlighted in Nutanix's best practices and security guidelines, which recommend changing default passwords as part of the initial configuration to ensure that the environment is not left vulnerable to unauthorized access due to known default credentials. This process is typically part of the initial setup procedures outlined in the Nutanix documentation for cluster deployment and security configuration.
The IPMI alert also points to the need for changing default passwords, but since IPMI (Intelligent Platform Management Interface) is not specifically mentioned in the provided options, it falls under the broader category of host-level password changes, which would be covered by option C.
BIOS password changes (Option B) and Password policy changes (Option D) are also important but were not directly flagged by the alerts mentioned. BIOS password changes are usually a separate task and not indicated by the alerts given, while password policy changes are related to the policies governing password complexity and rotation rather than the initial password setup.
Start a Discussions
Refer to the Exhibit:
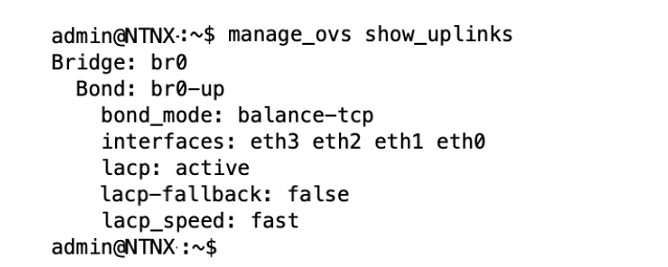
An administrator is adding a new node to a cluster. The node has been imaged to the same versions of AHV and AOS that the cluster is
running, configured with appropriate IP addresses, and br0-up has been configured in the same manner as the existing uplink bonds.
When attempting to add the node to the cluster with the Expand Cluster function in Prism, the cluster is unable to find the new node.
Based on the above output from the new node, what is most likely the cause of this issue?
Correct : B
The output in the exhibit indicates that the node's network interfaces (eth0-eth3) are bonded together using LACP (Link Aggregation Control Protocol) with 'balance-tcp' as the bonding mode and LACP speed set to 'fast'. For LACP to function correctly, the switch ports to which the node is connected must also be configured to support LACP. If the ports on the upstream switch are not configured for LACP, the bond will not be able to establish properly, and the node will not communicate effectively on the network, making it undiscoverable when attempting to expand the cluster.
The absence of an operational LACP configuration could prevent the new node from joining the existing cluster as the node's network interfaces would not be able to pass traffic correctly. This can be verified by checking the switch configuration to ensure that the ports are set to participate in an LACP bond.
The other options, such as a firewall blocking discovery traffic (Option A) or the node being on different VLANs (Option C), are possible causes for a node not being discovered, but given the specific command output provided, the most likely cause is related to the switch port configuration for LACP. Option D, regarding completing LACP configuration after cluster expansion, is not correct because LACP needs to be operational for the node to communicate with the cluster during the expansion process.
Proper LACP configuration is critical for network communication in a Nutanix AHV cluster, and this is covered in detail in the Nutanix AHV and Networking documentation. It outlines the steps for configuring network bonds and LACP on both the AHV hosts and the connecting network infrastructure.
Start a Discussions