Master Microsoft DP-600 Exam with Reliable Practice Questions
You have a Fabric tenant that contains a lakehouse.
You plan to query sales data files by using the SQL endpoint. The files will be in an Amazon Simple Storage Service (Amazon S3) storage bucket.
You need to recommend which file format to use and where to create a shortcut.
Which two actions should you include in the recommendation? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
Correct : C, D
You should use the Parquet format (B) for the sales data files because it is optimized for performance with large datasets in analytical processing and create a shortcut in the Tables section (D) to facilitate SQL queries through the lakehouse's SQL endpoint. Reference = The best practices for working with file formats and shortcuts in a lakehouse environment are covered in the lakehouse and SQL endpoint documentation provided by the cloud data platform services.
Start a Discussions
You have a Fabric tenant that contains a warehouse.
Several times a day. the performance of all warehouse queries degrades. You suspect that Fabric is throttling the compute used by the warehouse.
What should you use to identify whether throttling is occurring?
Correct : D
To identify whether throttling is occurring, you should use the Monitoring hub (B). This provides a centralized place where you can monitor and manage the health, performance, and reliability of your data estate, and see if the compute resources are being throttled. Reference = The use of the Monitoring hub for performance management and troubleshooting is detailed in the Azure Synapse Analytics documentation.
Start a Discussions
You have a Fabric tenant that contains a warehouse.
A user discovers that a report that usually takes two minutes to render has been running for 45 minutes and has still not rendered.
You need to identify what is preventing the report query from completing.
Which dynamic management view (DMV) should you use?
Correct : D
The correct DMV to identify what is preventing the report query from completing is sys.dm_pdw_exec_requests (D). This DMV is specific to Microsoft Analytics Platform System (previously known as SQL Data Warehouse), which is the environment assumed to be used here. It provides information about all queries and load commands currently running or that have recently run. Reference = You can find more about DMVs in the Microsoft documentation for Analytics Platform System.
Start a Discussions
You need to create a data loading pattern for a Type 1 slowly changing dimension (SCD).
Which two actions should you include in the process? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
Correct : A, D
For a Type 1 SCD, you should include actions that update rows when non-key attributes have changed (A), and insert new records when the natural key is a new value in the table (D). A Type 1 SCD does not track historical data, so you always overwrite the old data with the new data for a given key. Reference = Details on Type 1 slowly changing dimension patterns can be found in data warehousing literature and Microsoft's official documentation.
Start a Discussions
You are analyzing customer purchases in a Fabric notebook by using PySpanc You have the following DataFrames:

You need to join the DataFrames on the customer_id column. The solution must minimize data shuffling. You write the following code.

Which code should you run to populate the results DataFrame?
A)

B)

C)

D)
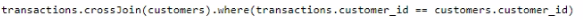
Correct : A
The correct code to populate the results DataFrame with minimal data shuffling is Option A. Using the broadcast function in PySpark is a way to minimize data movement by broadcasting the smaller DataFrame (customers) to each node in the cluster. This is ideal when one DataFrame is much smaller than the other, as in this case with customers. Reference = You can refer to the official Apache Spark documentation for more details on joins and the broadcast hint.
Start a Discussions